AIAA👐
Lecture 03
AI in Computer Vision part 2 - generative models 👁️
Welcome 👩🎤🧑🎤👨🎤
By the end of this lecture, we'll have learnt about:
The theoretical:
- Introduction to generative models in computer vision
- Introduction to VAE model
- Introduction to GAN model
- Introduction to Diffusion models
The practical:
- test(inference) GAN models on hugging face
- test(inference) Diffusion models on hugging face
First of all, don't forget to confirm your attendence on
SEAtS App! Three types of generative models in computer vision - different architectures and mechanisms
🤓 what are we talking about when we talk about "a model that can generate images"?
🤓 we are talking about:
- models that can *output* images: what does this tell you about the shape of the last layer of the model?
- - The number of neurons in the last layer = [the number of pixels * the number of color channels] in the desired output image.
🤓 we are talking about:
- models that can output images *according to some human instruction*
- - We'll see later that human instruction can come from the curation of training dataset and/or model's input layer.
🤓 we are talking about:
- models that can output images that do not look like the same every time: there should be some sort of randomness in the inference process.
- - We'll see later that all generative models have some sort of "sampling process" to get "randomly sampled vectors" that are of the same shape but have different values everytime sampled.
Let's move on to demystify the main three image generative model families, one by one 😎
- VAE: Variational AutoEncoder
- GAN: Generative Adversarial Networks
- Diffusion
😎 VAE is a variant of a neural net architecture called AE (Autoencoder)
Let's start from introducing the architecture of AE.
AE - the architecture 🤗
- 1. It is characterised by a bottleneck hidden layer - layer that has a *small* number of neuron which forces information to be compressed to have lower dimensions.
- 2. Training is done via reconstructing the input, i.e. the output layer tries to output exactly what is in the input layer.
- 3. This "encode - decoder" or "compress - decompress" setup may seem redundant, but doing so allows us to extract the "essence" representation from the bottleneck layer.
VAE - the architecture 🤗
Read
this article
- 1.The bottleneck layer of AE is deterministic - same input gets the same bottleneck representation.
- 2. VAE changes the deterministic bottleneck layer into a layer with a distribution ("randomness").
- 3. Check the article for why and how.
😎 Move onto GAN
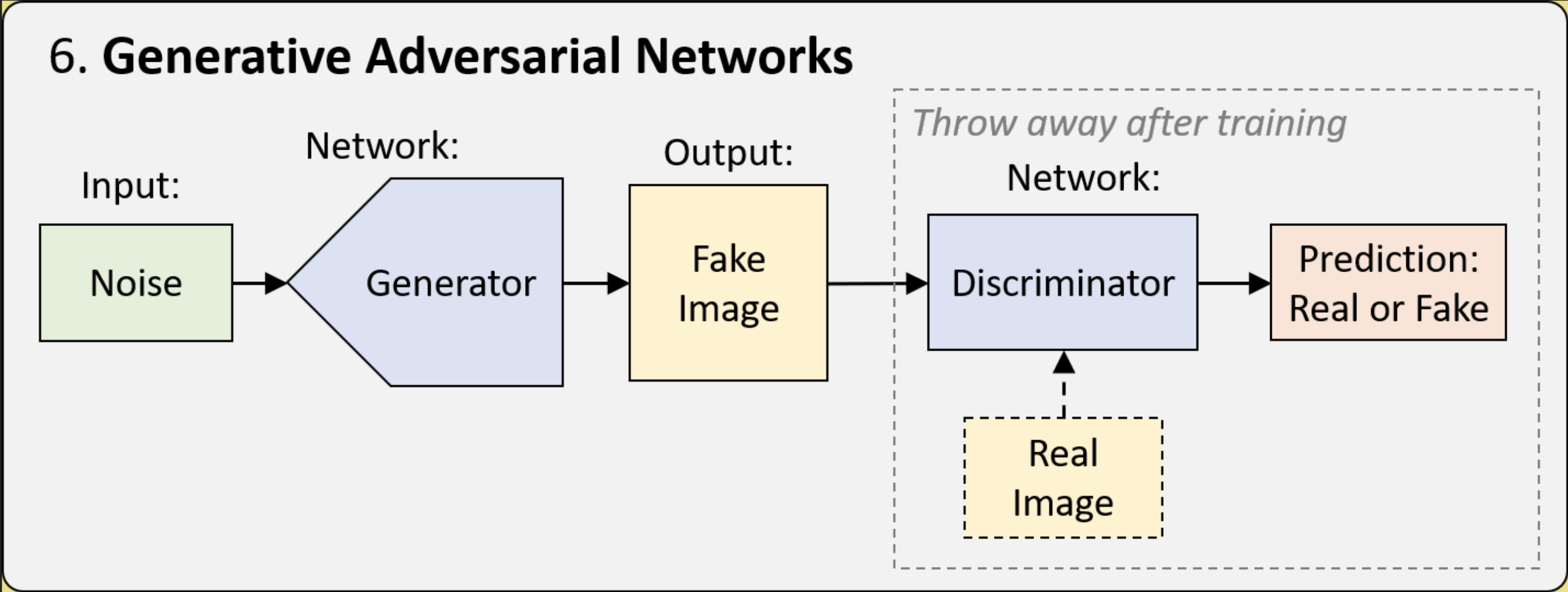
How does GAN work? 🕶️ the configuration:
- It is an ensemble of two neural networks - a Generator (G) and a Discriminator (D).
- We have a training dataset that comprises images that you want the model to model from, we would refer to these as "real" images, as opposed to the generated "fake" ones.
How does GAN work? 🕶️ what are the G and the D doing?
- Discriminator: a good old classification model that predicts if an image is real (from the training dataset) or fake (being generated).
- Generator: it take a random vector as input and outputs a 2D matrix as a generated image.
(no magic yet... we just set up two individual neural nets.)
How does GAN work? 🕶️ the training process:
- The magic happens when we train G and D alternatively in a particlar way:
- - It is a tom and jerry game between these two networks Generator 🐭 and Discriminator 🐈
- - where D tries to catch G as a fake image generator ️🕵️♀️
- - and G tries to fool D into thinking that G produces real images 🤡
Hands-on 🎳
- Let's take a look at this
google colab notebook for training a simple GAN
- - Which part of code corresponds to Generator?
- - Which part of code corresponds to Discriminator?
- - Which part of code corresponds to assemblying G and D losses ?
Problems of the vanilla GAN
- 😥It is notoriously unstable to train sometimes.
- 🥵Think about what happen if the D learns too fast and becomes a really good discriminator while the generator has barely learned anything?
(The generator can no longer get good supervision signal and just get stuck being a noise generator - in this case we have to terminate the training and start over again with a different settup, e.g. another random seed, etc. )
😎 Variants of GAN that performs better:
- WGAN
-
ProGAN (Progressive growing GAN)
-
StyleGAN
StyleGAN is the "industry-level" GAN which is behind thispersondoesnotexist and
more etc.
😎 Diffusion model! - high level understanding - level 0
- It's yet another generative model.
- Recall that the GAN model generates an image from some sampled random noise?
- Diffusion model also generates an image from some sampled random noise.
- Though the diffusion model deploys a very different mechanism for image denoising/generation.
😎 Diffusion model! - high level understanding - level 1
✌️There are two processes involved in training a diffusion
model: forward diffusion and backward diffusion.
- ⏩Forward diffusion: we start from a clear good image, and gradually add noises to it till it is completely noisy.
- ⏪Backward/reverse diffusion: we start from a noise-only image, and gradually remove noises from it till it becomes a clear good image.
- The actual generation process when inferencing a diffusion model is just that reverse diffusion process.
How about the text input, aka the multi-modal stuff?
- Let's read
this article
Homework:
- Inference
StyleGAN3 or
StyleGAN2 (choose one or more pre-trained models from the repos) on your laptop or workstation
- Train a
Pokemon GAN on your laptop or the workstation. Show me your pokemons!
- Inference a stable diffusion model from your laptop with the
hugging face library for stable diffusions, it is SO HANDY!
- SEND ME your dev note by next Monday!
- [Optional but highly rewarding] Train a StyleGANX on the workstation, using a custom dataset (think of an applicatin that is interesting to you!).
🕶️ What we have learnt today:
Three types of model family for generating images:
- VAE
- GAN
- Diffusion
- Inspect and inference examples of industry-level generative model: StyleGAN, Stable Diffusion
We'll see you next Monday same time and same place!